PCSK9
Cardiometabolic Disease: Big Data Tackles a Big Health Problem
Posted on by Dr. Francis Collins
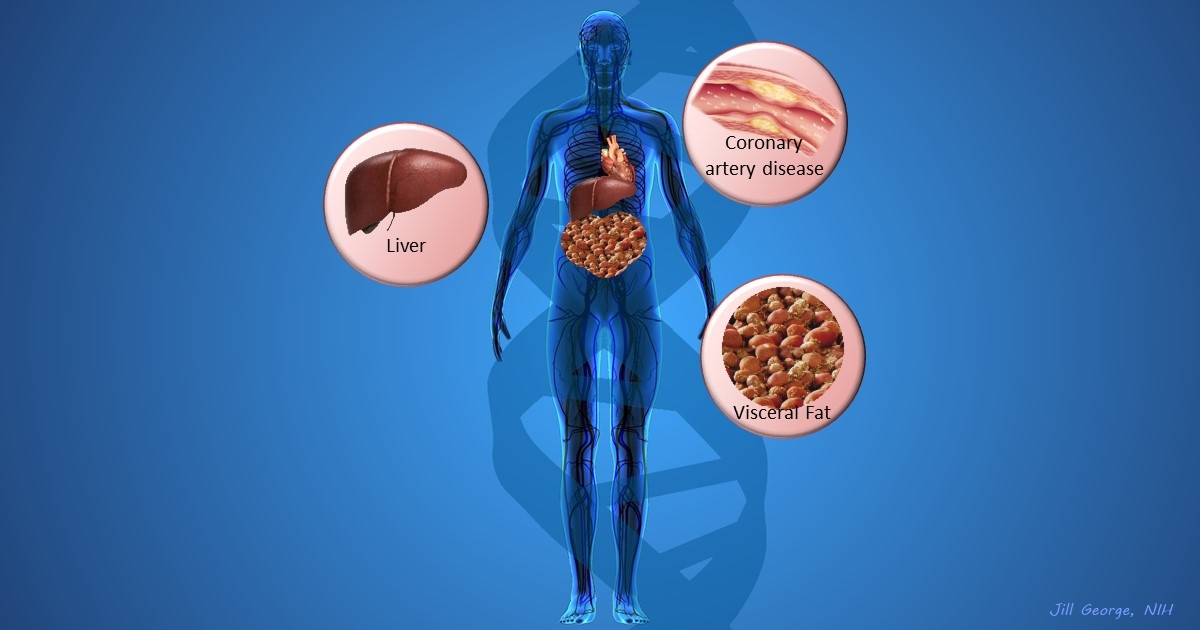
More and more studies are popping up that demonstrate the power of Big Data analyses to get at the underlying molecular pathology of some of our most common diseases. A great example, which may have flown a bit under the radar during the summer holidays, involves cardiometabolic disease. It’s an umbrella term for common vascular and metabolic conditions, including hypertension, impaired glucose and lipid metabolism, excess belly fat, and inflammation. All of these components of cardiometabolic disease can increase a person’s risk for a heart attack or stroke.
In the study, an international research team tapped into the power of genomic data to develop clearer pictures of the complex biocircuitry in seven types of vascular and metabolic tissue known to be affected by cardiometabolic disease: the liver, the heart’s aortic root, visceral abdominal fat, subcutaneous fat, internal mammary artery, skeletal muscle, and blood. The researchers found that while some circuits might regulate the level of gene expression in just one tissue, that’s often not the case. In fact, the researchers’ computational models show that such genetic circuitry can be organized into super networks that work together to influence how multiple tissues carry out fundamental life processes, such as metabolizing glucose or regulating lipid levels. When these networks are perturbed, perhaps by things like inherited variants that affect gene expression, or environmental influences such as a high-carb diet, sedentary lifestyle, the aging process, or infectious disease, the researchers’ modeling work suggests that multiple tissues can be affected, resulting in chronic, systemic disorders including cardiometabolic disease.
Introducing AMP: The Accelerating Medicines Partnership
Posted on by Dr. Francis Collins

It would seem like there’s never been a better time for drug development. Recent advances in genomics, proteomics, imaging, and other technologies have led to the discovery of more than a thousand risk factors for common diseases—biological changes that ought to hold promise as targets for drugs.
But this deluge of new opportunities has to be put in context: drug development is a terribly difficult business. To the dismay of researchers, drug companies, and patients alike, the vast majority of drugs entering the development pipeline fall by the wayside. The most distressing failures occur when a drug is found to be ineffective in the later stages of development—in Phase II or Phase III clinical studies—after years of work and millions of dollars have already been spent [1]. Why is this happening? One major reason is that we’re not selecting the right biological changes to target from the start.