In Alzheimer’s disease, a buildup of sticky amyloid proteins in the brain clump together to form plaques, causing damage that gradually leads to worsening dementia symptoms. A promising way to change the course of this disease is with treatments that clear away damaging amyloid plaques or stop them from forming...
In Alzheimer’s disease, a buildup of sticky amyloid proteins in the brain clump together to form plaques, causing damage that gradually leads to worsening dementia symptoms. A promising way to change the course of this disease is with treatments that clear away damaging amyloid plaques or stop them from forming in the first place. In fact, the Food and Drug Administration recently approved the first drug for early Alzheimer’s that moderately slows cognitive decline by reducing amyloid plaques. Still, more progress is needed to combat this devastating disease that as many as 6.7 million Americans were living with in 2023.
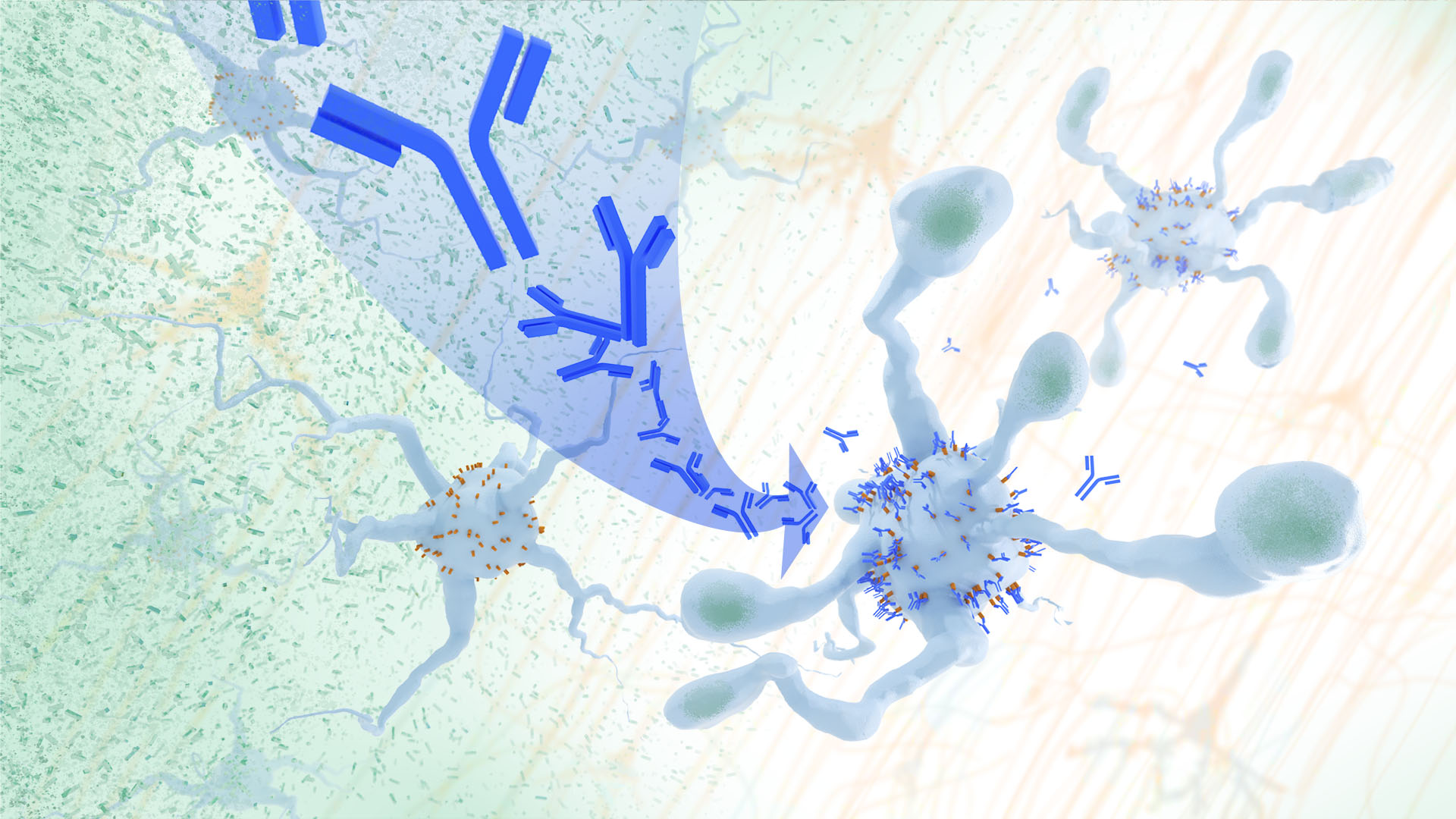
Recent findings from a study in mice, supported in part by NIH and reported in Science Translational Medicine, offer another potential way to clear amyloid plaques in the brain. The key component of this strategy is using the brain’s built-in cleanup crew for amyloid plaques and other waste products: immune cells known as microglia that naturally help to limit the progression of Alzheimer’s. The findings suggest it may be possible to develop immunotherapies—treatments that use the body’s immune system to fight disease—to activate microglia in the brains of people with Alzheimer’s and clear amyloid plaques more effectively.
Pregnancy and childbirth are often thought of as joyful times. Yet, we know that mental health conditions including perinatal depression, anxiety, and post-traumatic stress disorder (PTSD) are common complications during and after pregnancy, and this is contributing to a maternal health crisis in this country.
Now, a trio of NIH-supported studies reported in the journal Health Affairs show that diagnosis and treatment of mental health conditions such as anxiety, depression, and PTSD during pregnancy and in the first year after giving birth rose significantly in Americans with private health insurance from 2008 to 2020. While these are encouraging signs of increasing mental health awareness and service use, these studies also showed that this increase hasn’t happened equally across all demographic groups and states, making it clear there’s more work to do to ensure that people from all walks of life have access to the care they need, regardless of their race, ethnicity, geographic location, financial status, or other factors.
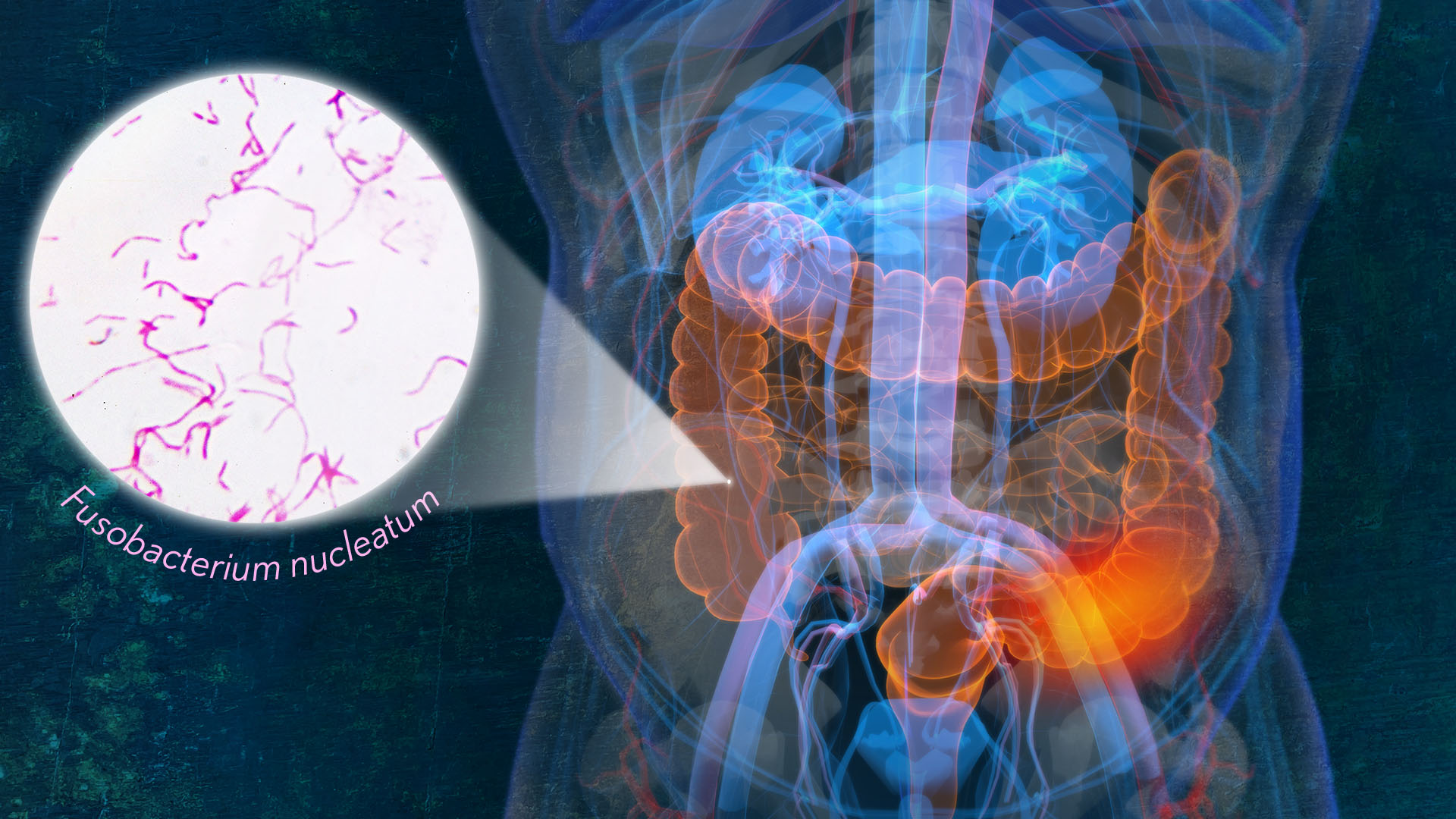
Colorectal cancer is a leading cause of death from cancer in the United States. We know that risk of colorectal cancer goes up with age, certain coexisting health conditions, family history, smoking, alcohol use, and other factors. Researchers are also trying to learn more about what leads colorectal cancer to grow and spread. Now, findings from a new study supported in part by NIH add to evidence that colorectal tumor growth may be driven by a surprising bad actor: a microbe that’s normally found in the mouth.
There’s a good reason you feel fear creep in when you’re walking alone at night in an unfamiliar place or hear a loud and unexpected noise ring out. In those moments, your brain triggers other parts of your nervous system to set a stress response in motion throughout your body. It’s that fear-driven survival response that keeps you alert, ready to fight or flee if the need arises. But when acute anxiety or traumatic events lead to fear that becomes generalized—occurring often and in situations that aren’t threatening—this can lead to debilitating anxiety disorders, including post-traumatic stress disorder (PTSD).
Just what happens in the brain’s circuitry to turn a healthy fear response into one that’s harmful hasn’t been well understood. Now, research findings by a team led by Nicholas Spitzer and Hui-Quan Li at the University of California San Diego and reported in the journal Science have pinpointed changes in the biochemistry of the brain and neural circuitry that lead to generalized fear.1 The intriguing findings, from research supported in part by NIH, raise the possibility that it might be possible to prevent or reverse this process with treatments targeting this fear “switch.”