human ancestry
Seeking Consensus on the Use of Population Descriptors in Genomics
Posted on by Eric Green, M.D., Ph.D., National Human Genome Research Institute
Cataloging and characterizing the thousands of genomic variants—differences in DNA sequences among individuals—across human populations is a foundational component of genomics. Scientists from various disciplinary fields compare the variation that occurs within and between the genomes of individuals and groups. Such efforts include attributing descriptors to population groups, which have historically included the use of social constructs such as race, ethnicity, ancestry, and political geographic location. Like any descriptors, these words do not fully account for the scope and diversity of the human species.
The use of race, ethnicity, and ancestry as descriptors of population groups in biomedical and genomics research has been a topic of consistent and rigorous debate within the scientific community. Human health, disease, and ancestry are all tied to how we define and explain human diversity. For centuries, scientists have incorrectly inferred that people of different races reflect discrete biological groups, which has led to deep-rooted health inequities and reinforced scientific racism.
In recent decades, genomics research has revealed the complexity of human genomic variation and the limitations of these socially derived population descriptors. The scientific community has long worked to move beyond the use of the social construct of race as a population descriptor and provide guidance about agreed-upon descriptors of human populations. Such a need has escalated with the growing numbers of large population-scale genomics studies being launched around the world, including in the United States.
To answer this call, NIH is sponsoring a National Academies of Sciences, Engineering, and Medicine (NASEM) study that aims to develop best practices in the use of race, ethnicity, and genetic ancestry in genomics research. The NASEM study is sponsored by 14 NIH institutes, centers, offices, and programs, and the resulting report will be released in February 2023.
Experts from various fields—including genomics, medicine, and social sciences—are conducting the study. Much of the effort will revolve around reviewing and assessing existing methodologies, benefits, and challenges in the use of race and ethnicity and other population descriptors in genomics research. The ad hoc committee will host three public meetings to obtain input. Look for more information regarding the committee’s next public session planned for April 2022 on the NASEM “Race, Ethnicity, and Ancestry as Population Descriptors in Genomics Research” website.
To further underscore the need for the NASEM study, an NIH study published in December 2021 revealed that the descriptors for human populations used in the genetics literature have evolved over the last 70 years [1]. For example, the use of the word “race” has substantially decreased, while the uses of “ancestry” and “ethnicity” have increased. The study provided additional evidence that population descriptors often reflect fluid, social constructs whose intention is to describe groups with common genetic ancestry. These findings reinforce the timeliness of the NASEM study, with the clear need for experts to provide guidance for establishing more stable and meaningful population descriptors for use in future genomics studies.
The full promise of genomics, including its application to medicine, depends on improving how we explain human genomic variation. The words that we use to describe participants in research studies and populations must be transparent, thoughtful, and consistent—in addition to avoiding the perpetuation of structural racism. The best and most fruitful genomics research demands a better approach.
Reference:
[1] Evolving use of ancestry, ethnicity, and race in genetics research—A survey spanning seven decades. Byeon YJJ, Islamaj R, Yeganova L, Wilbur WJ, Lu Z, Brody LC, Bonham VL. Am J Hum Genet. 2021 Dec 2;108(12):2215-2223.
Links:
Use of Race, Ethnicity, and Ancestry as Population Descriptors in Genomics Research (National Academies of Sciences, Engineering, and Medicine)
“Language used by researchers to describe human populations has evolved over the last 70 years.” (National Human Genome Research Institute/NIH)
Genomic Variation Program (NHGRI)
[Note: Acting NIH Director Lawrence Tabak has asked the heads of NIH’s institutes and centers to contribute occasional guest posts to the blog as a way to highlight some of the cool science that they support and conduct. This is the third in the series of NIH institute and center guest posts that will run until a new permanent NIH director is in place.]
Crowdsourcing 600 Years of Human History
Posted on by Dr. Francis Collins
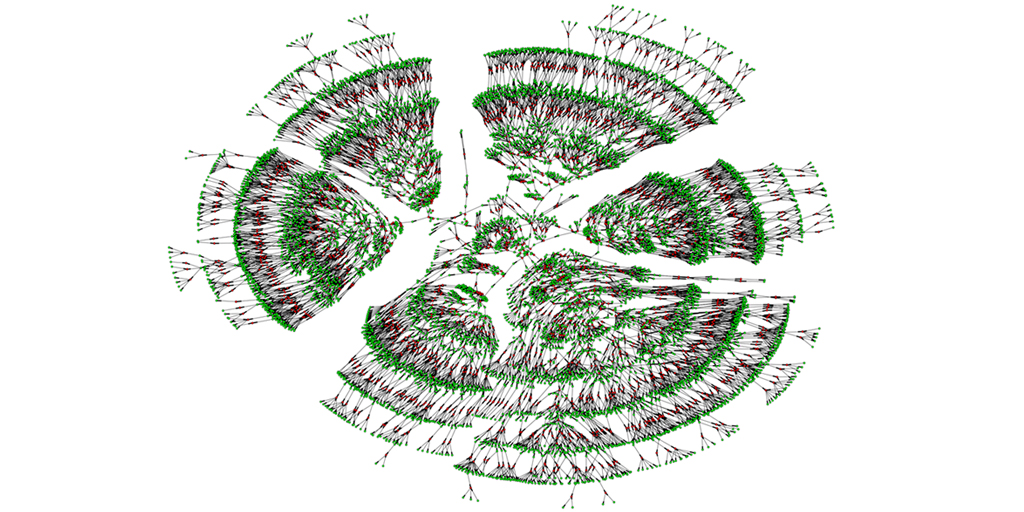
Caption: A 6,000-person family tree, showing individuals spanning seven generations (green) and their marital links (red).
Credit: Columbia University, New York City
You may have worked on constructing your family tree, perhaps listing your ancestry back to your great-grandparents. Or with so many public records now available online, you may have even uncovered enough information to discover some unexpected long-lost relatives. Or maybe you’ve even submitted a DNA sample to one of the commercial sources to see what you could learn about your ancestry. But just how big can a family tree grow using today’s genealogical tools?
A recent paper offers a truly eye-opening answer. With permission to download the publicly available, online profiles of 86 million genealogy hobbyists, most of European descent, the researchers assembled more than 5 million family trees. The largest totaled more than 13 million people! By merging each tree from the crowd-sourced and public data, including the relatively modest 6,000-person seedling shown above, the researchers were able to go back 11 generations on average to the 15th century and the days of Christopher Columbus. Doubly exciting, these large datasets offer a powerful new resource to study human health, having already provided some novel insights into our family structures, genes, and longevity.
Out of Africa: DNA Analysis Points to a Single Major Exodus
Posted on by Dr. Francis Collins

Credit: NASA
If you go back far enough, the ancestors of all people trace to Africa. That much is clear. We are all Africans. But there’s been considerable room for debate about exactly when and how many times modern humans made their way out of Africa to take up residence in distant locations throughout the world. It’s also unclear what evolutionary or other factors might have driven our human ancestors to set off on such a perilous and uncertain journey (or journeys) in the first place.
By analyzing 787 newly sequenced complete human genomes representing more than 280 diverse and understudied populations, three new studies—two of which received NIH funding—now help to fill in some of those missing pages of our evolutionary history. The genomic evidence suggests that the earliest human inhabitants of Eurasia came from Africa and began to diverge genetically at least 50,000 years ago. While the new studies differ somewhat in their conclusions, the findings also lend support to the notion that our modern human ancestors dispersed out of Africa primarily in a single migratory event. If an earlier and ultimately failed voyage occurred, it left little trace in the genomes of people alive today.